
Our article has recently been accepted for publication. If you use this database, please make sure to cite us! Thanks very much.
- Hout, M. C., Goldinger, S. D., & Brady, K. J. (2014). MM-MDS: A multidimensional scaling database with similarity ratings for 240 object categories from the Massive Memory picture database. PLoS ONE, 9: e112644. doi: 10.1371/journal.pone.0112644.
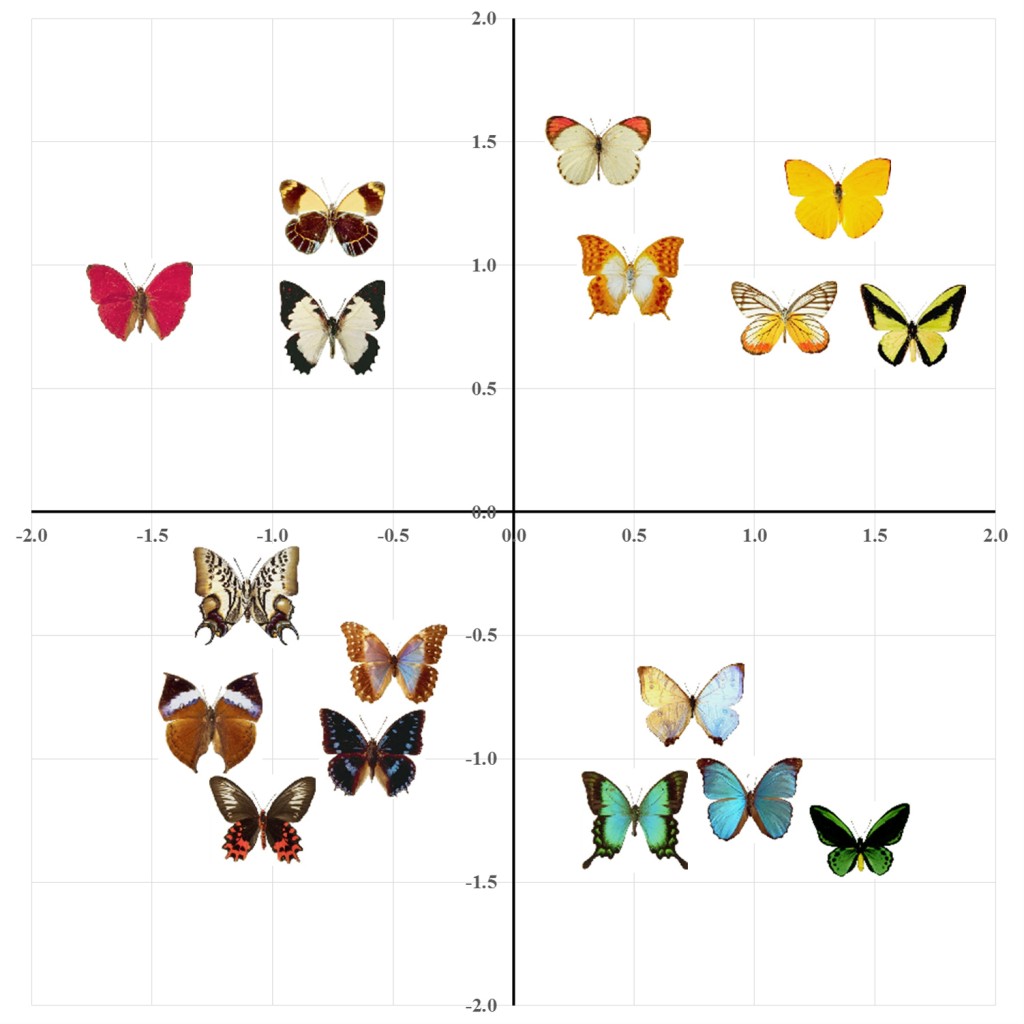
Researchers across domains of cognitive science (and related fields) often require stimuli with varying degrees of similarity to one another. For instance, someone interested in visual search may wish to know whether attention is drawn to foils that are more or less similar to a designated target object (e.g., Hout & Goldinger, in press). Or a recognition memory investigator may wish to control the difficulty of a discriminating target and lure objects (e.g., Hout & Goldinger, 2012). Empirically, however, manipulating or measuring the similarity of stimulus items can be a challenging task.
One approach is to employ simplistic stimuli, and vary a single feature of each item, such as the color or orientation of a rectangular bar (e.g., Treisman, 1991). This is a suboptimal approach with higher-level vision, however, because real-world objects contain many features that may be ill-defined or inconsistent across exemplars of a category. Restricting stimulus complexity to simple, arbitrary objects (e.g., rotated, colored shapes) permits tight experimental control; visual similarity across items is easily assessed and manipulated. But natural perception rarely involves objects defined by minimal arbitrary features, such as “red, 45-degree rotation, rectangular.” To help researchers better address ecologically valid perception, we created a large-scale database, evaluating psychological similarity among multiple exemplars from 240 object categories. We used multidimensional scaling (MDS) to identify objects with varying degrees of similarity to one another (see Migo, Montaldi, & Mayes, 2013, for a similar approach). One appealing aspect of MDS is that it allows people to provide similarity estimates based on whatever featural dimensions they consider salient or important. MDS does not require a priori identification of feature dimensions, or arbitrary rating schemes, such as ranking the similarity of colored bars based on degree of rotation, or distance in RGB color space.
We collected similarity ratings on pictures of real-world objects; things that people encounter in everyday life, defined by many features simultaneously. These stimuli afford researchers flexibility in item selection, as they can choose pictures with featural variation without compromising the categorical identity of the exemplars. All stimuli came from the “Massive Memory” database (Brady, Konkle, Alvarez & Oliva, 2008; Konkle, Brady, Alvarez & Oliva, 2010; cvcl.mit.edu/MM/stimuli.html). We selected a large variety of semantically-matched pictures: 200 object categories were represented by 17 individual exemplars each, and another 40 categories by 16 exemplars each. We then obtained MDS solutions for each image category (e.g., an MDS space of 17 coffee mugs, or 16 lamps). These “psychological spaces” were used to identify stimulus pairings with varying degrees of similarity. The logic is simple: By using the MDS spaces, pairs of images can be identified that are similar or dissimilar, indexed by their proximity in psychological space. We were thus able to define pairwise similarity along a continuum of psychological distances. This technique is appealing because it provides similarity ratings that are psychologically grounded, rather than defined arbitrarily, and because the large sets of category exemplars provide many stimulus pairings for researchers to draw upon.
Similarity ratings and multidimensional scaling.
MDS is a tool by which researchers can obtain quantitative estimates of the similarity among groups of items (Hout, Papesh & Goldinger, 2013). More specifically, MDS is a set of statistical techniques that takes as input item-to-item similarity ratings. It then uses data-reduction procedures to minimize the complexity of the similarity matrix, permitting (in many cases) a visual appreciation of the underlying relational structures that were used to govern the similarity ratings.
Likely the most common method for obtaining similarity estimates is simply to ask people to numerically rate object pairs via Likert scales. In this technique, ratings are collected for every possible pairwise combination of stimuli (e.g., “respond ‘1’ when the items are most similar and ‘9’ when the pair is most dissimilar”). This pairwise method is useful and simple to implement. However, when the set of stimuli to be scaled is large, this technique is not ideal: The number of comparisons necessary to fill an item-to-item similarity (or proximity) matrix grows rapidly as a function of stimulus set size, leading to lengthy experimental protocols. Data collection becomes cumbersome, and concerns therefore arise regarding the vigilance of the raters (see Hout, Goldinger & Ferguson, 2013).
An alternative way to collect similarity estimates is the spatial arrangement method (SpAM), originally proposed by Goldstone (1994; see also Kriegeskorte & Marieke, 2012). This technique is faster and more efficient than the pairwise method, and produces output data of equal quality, relative to its more well-established counterpart (Hout et al., 2013). Here, many (or all) of the to-be-rated stimuli are presented at once, and participants move the items around on the computer screen, placing them at distances from one another that reflect subjective similarity estimates (items that are rated as similar are placed close to one another, and dissimilar items are placed proportionately farther away). The task can be conceptualized as having people project their own psychological spaces onto a two-dimensional plane (i.e., the computer screen). Once the participant has finished organizing the space, a proximity matrix is derived from the pairwise Euclidean distances (measured in pixels) between every pair of items. This technique is extremely well-suited for collecting large quantities of MDS data in relatively short periods of time (a set of 17 stimuli would be scaled in roughly 20 minutes using the pairwise method, whereas SpAM would likely be completed in under 5 minutes).